本文基于黑马2022的Redis课程原理篇编写,课程地址:黑马程序员Redis入门到实战教程,深度透析redis底层原理+redis分布式锁+企业解决方案+黑马点评实战项目
引言
Redis性能卓越的关键在于其所有操作都基于内存。然而,单个Redis节点的内存不宜设置过大,否则会影响持久化或主从同步的性能。
因此,通常在配置文件中通过 maxmemory 参数设置Redis的最大内存限制(例如 maxmemory 1gb)。当内存使用达到上限时,将无法存储更多数据。
为解决此问题,Redis提供了两种主要的内存管理策略:
- 过期策略
- 内存淘汰策略
过期策略
核心问题
过期策略通过 expire 命令为key设置TTL(Time To Live,存活时间)。例如:
|
|
在TTL到期前访问该key可获取值,到期后访问则返回 (nil),表明key已被删除,内存得以回收。
这引出了两个核心原理问题:
- Redis是如何知道一个key是否过期的?
- key过期后,是立即被删除吗?
数据库结构
Redis内部默认有16个数据库(编号0-15),每个数据库对应一个 redisDb 结构体。该结构体是理解过期策略的基础。

dict *dict;:键空间。这是一个字典,存储了该数据库中所有的key-value对。key和value都以redisObject指针形式存储。dict *expires;:过期字典。这个字典专门存储那些设置了过期时间的key。其键(key)与dict字典中的键相同,指向同一个redisObject;但其值(value)不是原value,而是该key对应的 过期时间戳(TTL)。- 其他属性如
blocking_keys,watched_keys,id,avg_ttl等用于特定功能或统计,当前阶段非核心。
下面是redisDb 两个核心字典 dict 和 expires的结构关系图:
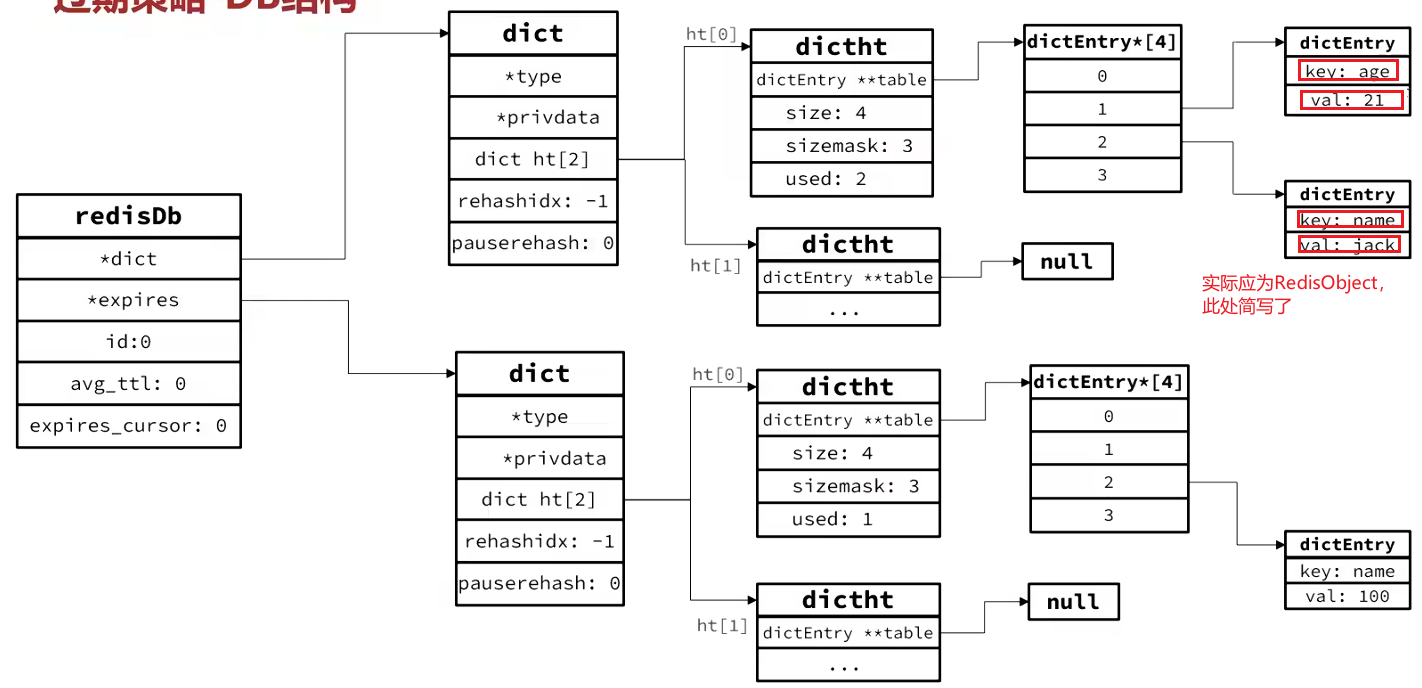
dict(键空间)负责存储所有键值对。expires字典仅存储设置了过期时间的key及其过期时间戳。因此,expires中的元素数量<=dict中的元素数量。- 当查询一个key是否过期时,Redis会从
expires字典中查找该key,获取其过期时间戳并与当前时间比较。
现在就可以回答前面的第一个问题了,Redis是如何知道一个key是否过期的?
是利用两个Dict分别记录key-value键值对和key-ttl键值对
过期key的删除策略
第二个问题,*key过期后,是立即被删除吗?*答案是不会
Redis 不会 在key过期的那一刻立即删除它。因为为海量的key都设置定时器会极大消耗CPU资源,影响Redis服务性能。因此,Redis采用了两种策略的组合:
- 惰性删除
- 周期删除
惰性删除
并非在TTL到期后立即删除,而是在下一次访问该key时,再检查其是否过期。如果过期,则执行删除操作。
Redis在执行任何对key的增删改查(如 lookupKeyWriteWithFlags, lookupKeyReadWithFlags)操作时,都会先调用 expireIfNeeded(db, key) 函数。
该函数的核心逻辑是,在 expires 字典中查找key,获取过期时间,与当前时间比较。若已过期,则调用 deleteExpiredKeyAndPropagate(db, key) 进行删除并同步(如有必要),然后返回删除结果。

优点是对CPU友好,删除操作只在必要时发生。
但缺点是,如果一个过期key再也没有被访问,它将永远不会被删除,会造成内存泄漏。因此,惰性删除需要配合定期删除。
周期删除
通过一个定时任务,周期性地抽样检查一部分过期key,并执行删除操作。此任务会不断遍历数据库,最终覆盖所有key。
两种触发方式:
- SLOW模式(慢模式): 在Redis服务器初始化时设置一个定时任务,执行
serverCron()函数。其执行频率由server.hz配置(默认为10,即每秒10次,每100ms执行一次)。此模式执行时间较长(但受控),频率较低。 - FAST模式(快模式): 在Redis事件循环的每一个周期开始前,调用
beforeSleep()函数,其中会执行一次activeExpireCycle(ACTIVE_EXPIRE_CYCLE_FAST)。此模式执行时间极短(不超过1ms),频率高(与事件循环频率相同,但两次间隔不低于2ms)。

共同执行流程(activeExpireCycle函数):
-
遍历所有数据库(0-15)。
-
对于每个数据库的
expires字典,逐个遍历其哈希表桶(bucket)。 -
从每个桶中抽样(例如,SLOW模式每次抽样约20个key)检查key是否过期。
-
如果发现过期key,则删除它。
-
删除后,会检查两个停止条件:(若不满足停止条件,则会继续循环)
- 时间限制: SLOW模式总执行时间不超过周期(100ms)的25%(即25ms);FAST模式不超过1ms。
- 比例限制: 如果本次抽样中,过期key的比例低于10%,则认为过期key已不多,可以提前结束本次清理任务。
对比
| 特性 | SLOW模式 | FAST模式 |
|---|---|---|
| 触发位置 | serverCron() 定时任务 |
beforeSleep() 事件循环回调 |
| 执行频率 | 低频(默认10Hz,100ms/次) | 高频(与事件循环频率同步) |
| 单次执行时长 | 较长,但严格控制(不超过25ms) | 极短(严格不超过1ms) |
| 主要目的 | 深度清理,处理大量积压的过期key | 快速清理,避免阻塞主线程 |
| 影响 | 可能带来短暂的性能波动 | 对主线程几乎无阻塞 |
关键参数与公式:
- SLOW模式下任务执行周期
period=1000 / server.hzms。若server.hz=10,则period=100ms - SLOW模式单次清理最大耗时为period×25%
- FAST模式单次清理最大耗时要≤1ms
- 两种模式都会在抽样后检查:如果
expired_count / sampled_count < 10%,则提前结束本次任务
淘汰策略
在数据量巨大的项目中,即使删除了所有过期 key,Redis 内存也可能达到设置的上限(maxmemory),无法满足新的数据写入需求。
所以引入 内存淘汰策略。当 Redis 内存使用达到 maxmemory 阈值时,主动挑选一部分 key 进行删除(无论这些 key 是否过期),以释放内存空间。
何时检查与淘汰?
Redis 在任何命令执行之前,都会检查内存是否充足。如果不足,会尝试调用 performEvictions 函数进行内存清理。
|
|
如果 performEvictions() 返回失败(EVICT_FAIL),表示内存仍不足,根据配置决定是直接拒绝命令(报 OOM 错误)还是放任不管
挑选哪些key?
Redis 提供了多种策略来决定淘汰哪些 key。
八种内存淘汰策略
Redis 通过配置 maxmemory-policy 来选择策略。
| 策略名称 | 淘汰范围 | 算法/选择依据 | 说明 |
|---|---|---|---|
| noeviction | - | - | 默认策略。不淘汰任何 key。当内存已满,尝试写入新数据时,Redis 将直接返回错误。 |
| volatile-ttl | 带过期时间的 key (expires 字典) |
TTL 值 | 优先淘汰剩余存活时间(TTL)最短的 key。 |
| allkeys-random | 所有 key (dict 字典) |
随机 | 从所有 key 中随机选择一个进行淘汰。 |
| volatile-random | 带过期时间的 key (expires 字典) |
随机 | 从设置了过期时间的 key 中随机选择一个进行淘汰。 |
| allkeys-lru | 所有 key (dict 字典) |
LRU | 对所有 key,基于 LRU(Least Recently Used) 算法进行淘汰。 |
| volatile-lru | 带过期时间的 key (expires 字典) |
LRU | 对设置了过期时间的 key,基于 LRU 算法进行淘汰。 |
| allkeys-lfu | 所有 key (dict 字典) |
LFU | 对所有 key,基于 LFU(Least Frequently Used) 算法进行淘汰。 |
| volatile-lfu | 带过期时间的 key (expires 字典) |
LFU | 对设置了过期时间的 key,基于 LFU 算法进行淘汰。 |
在生产环境中,需要根据业务数据访问模式(是否倾向于最近访问或高频访问)来选择合适的 maxmemory-policy。通常 allkeys-lru 是一个比较通用且高效的选择。
配置方式:
|
|
LRU 与 LFU 算法
每个 Redis 的值(key-value 中的 value)在内存中都被封装成一个 redisObject 结构体:
|
|
lru这个 24 位字段的含义取决于配置的淘汰策略 (maxmemory-policy):
- 当使用 LRU 算法时,记录的是最近一次访问的时间戳(秒)。
- LRU = Least Recently Used (最少最近使用)。
- 淘汰标准:
当前时间 - lru值的差值越大(即 key 越久没被访问),其“空闲时间”(idletime)越大,优先被淘汰。 - 注意:很多人误译为“最近最少使用”,这是错误的。正确翻译是“最少最近使用”,关注的是“最近一次使用时间”这个点。
- 当使用 LFU 算法时,这 24 位被拆分为两部分:
- LFU = Least Frequently Used (最少频率使用)。
- 高 16 位:记录最近一次访问的时间戳(分钟为单位)。
- 低 8 位:记录 “逻辑访问次数”(Logical Access Counter)。
- 淘汰标准:逻辑访问次数值越小(代表访问频率低),优先被淘汰。
LFU 逻辑访问次数的计算原理:
LFU 并不是简单计数,而是一种概率性、带衰减的计数器,用很小的空间(8bit)近似统计访问频率。 计算过程(当 key 被访问时):
- 生成一个 0~1 之间的随机数 R。
- 用旧的逻辑访问次数 乘以
lfu_log_factor(默认值 10),再 +1,然后取其倒数得到概率 P。 P=1/(旧次数×lfu_log_factor+1) - 比较 R 和 P:如果 R < P,则逻辑访问次数 +1(最大不超过 255)。
- 访问次数会随时间衰减。公式为
当前逻辑访问次数 = max(0, 旧次数 - floor(距离上次访问的时间/lfu_decay_time))。lfu_decay_time默认 1 分钟。
在配置文件 redis.conf 中修改对应策略:
|
|
performEvictions 淘汰流程
Redis 采用了近似 LRU/LFU 算法,通过维护一个 eviction pool(淘汰池) 和采样比较来高效执行淘汰,避免全量扫描所有 key。大致流程如下图:
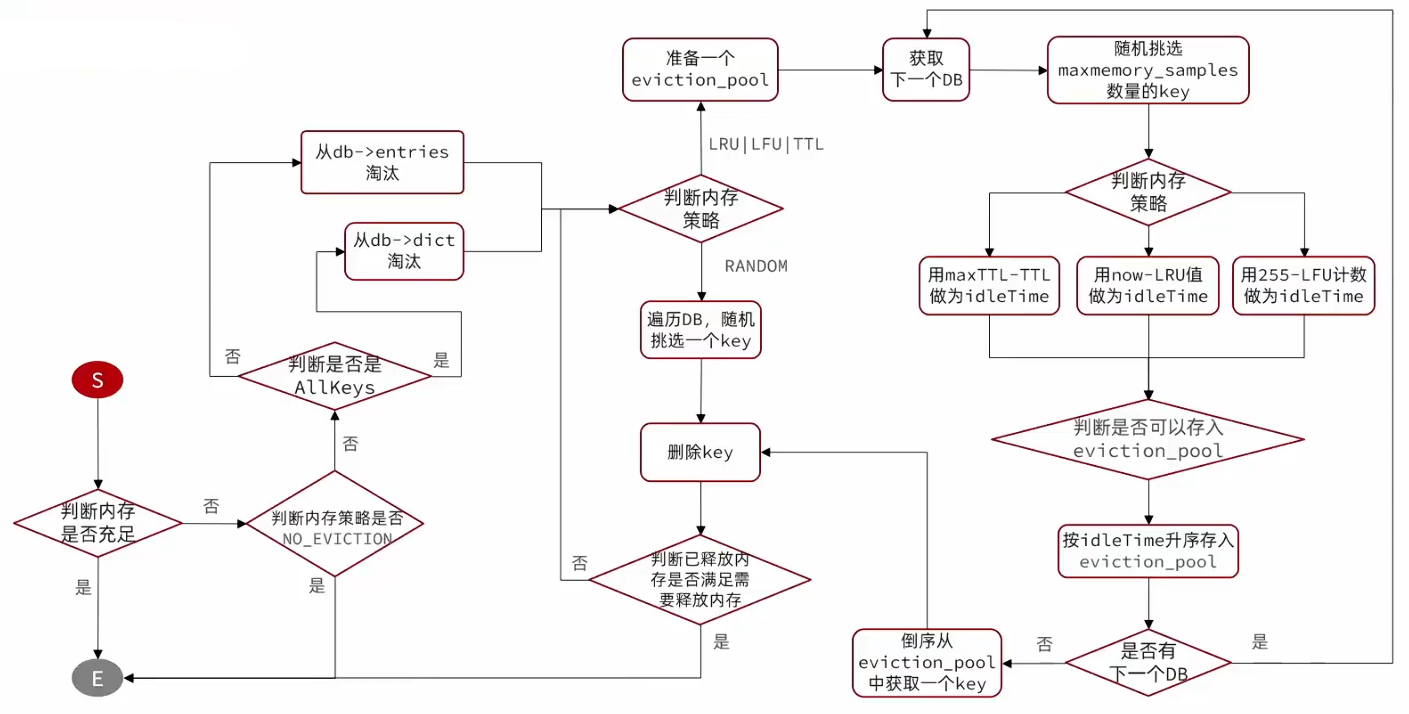
- eviction pool 的作用:从所有 key 中随机采样一批,然后只从这批样本中挑选出“最应该被淘汰”的 key 放入池中。最终从池中淘汰。这是一种空间换时间的优化,平衡了性能和准确性。默认大小为16。
- idle time 的计算:为了统一将各种策略(LRU, LFU, TTL)映射到同一个“idle time”概念上,便于比较和排序。
- LRU 策略:
idle time = 当前时间 - lru 时间戳(秒) - LFU 策略:
idle time = 255 - 逻辑访问次数(逻辑访问次数越小,idle time 越大) - TTL 策略:
idle time = Long型最大值 - 剩余TTL值(剩余时间越短,idle time 越大) - Random 策略:不使用 eviction pool,直接随机挑选并删除。
- LRU 策略:
- maxmemory_samples 参数:每次从数据库中随机挑选的 key 数量(默认 5)。值越大,淘汰越精确,但 CPU 开销也越大。